
软件详情
各位游戏爱好者们,今天要和大家聊聊两个超级强劲的AI助手工具,DeepSeek和豆包,这可是一场关于力量与能力的较量啊!DeepSeek刚推出的手机版v3自动引起了很多关注,人们甚至称其为“大模型之王”!那么这两个模型各自的优势是什么呢?我将为大家深入对比一下,让你在寻找合适的AI助手时不再迷茫。
了解DeepSeek和豆包的强大实力
(一)DeepSeek在密文解码方面表现优异,空间推理却稍显逊色于豆包
从逻辑推理来看,DeepSeek在密文解码方面的能力非常出众,毫不夸张地说,它在这个任务中简直是个天才。而豆包可谓是空间推理的高手,能够灵活理解文字描述。例如,当我们考察“城市-你的住处-农场-机场”这个关系时,DeepSeek和通义千问在推断时犯了错误,而豆包则展现了它对二维平面空间的深刻理解,得出了正确的远近关系。
在密文解码任务中,DeepSeek以其卓越的推理能力脱颖而出,能够解码出正确的文本内容。“The Model trained with reinforcement learning to perform complex reasoning”,这句话的解码结果全靠它。尽管通义千问的结果也比较接近,但豆包和Kimi的表现则逊色不少。

DeepSeek的几何与数学能力如何?
(二)DeepSeek在空间几何和数学计算方面与行业平均水平齐平
关于空间几何的理解和计算,各大模型的表现都显得相对接近。经过测试,DeepSeek、Kimi和通义千问无一例外地给出了详细的计算过程,结果也没有偏差。然而,大家有没有发现它们在用户指令“画出圆柱体在水平面上的正投影和侧投影”这一点上,全都没能准确完成?相比之下,豆包虽然画出了正投影和侧投影,但在计算上却失误了。
至于数学能力,DeepSeek、豆包和Kimi在计算过程中表现持续良好,给出的步骤和理由也都令人信服,然而通义千问在这方面略显不慎,结果出现了错误。

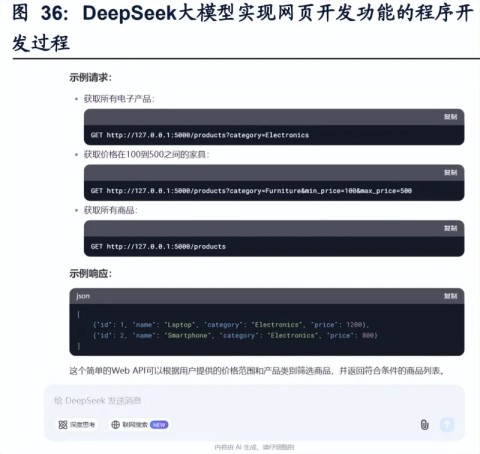
针对程序开发,DeepSeek的表现是否更胜一筹?
(三)DeepSeek生成的内容更符合开发者的需求
在简单的代码生成上,四个模型之间的差距不大。在代码实现方面,DeepSeek和通义千问都对生成的每段代码进行了注释,并且解释了算法的实现原理。至于豆包和Kimi,它们的代码解释也相当详细,但总体上DeepSeek的引导更为全面。
尤其在特定应用场景中,DeepSeek和豆包展现了各自的开发能力,能逐步引导用户理解每个步骤,这对于程序员朋友们真是太重要了。相比之下,Kimi和通义千问在这方面的解释则显得有些薄弱。
DeepSeek在文本生成方面是否具备行业竞争力?
(四)DeepSeek生成文本的质量令其具有一定信誉
说到文本创作,通义千问在生成的长度上稍微多了点,但在内容的实际应用中,该注意的还是简洁性!在描述季节以及求职场景等方面,四款模型都能完成任务,表现非常不错。Kimi的生成长度控制在600字以内,DeepSeek和豆包都在700字左右,而通义千问则超过了1000字,虽然这样在字数上看起来很有优势,但在实际应用中却可能显得冗长。
软件亮点
1. 利用AI技术,提供高效的对话和信息检索;
2. 支持多种场景,兼具工作和娱乐功能,无论你有多样化的需求,它都能迎合;
3. 不断升级的AI模型更是保证了软件的长久价值。


 ai智能助手app合集
ai智能助手app合集
 AI写论文
AI写论文
 微软AI绘画
微软AI绘画
 森林AI美术
森林AI美术
 万能AI盒子
万能AI盒子
 百智AI
百智AI
 AI扫描狗
AI扫描狗
网友评论